Reklama
Ste veriaci v myšlienku, že akonáhle bude niečo zverejnené na internete, bude publikované navždy? Dnes sa chystáme rozptýliť tento mýtus.
Pravda je, že v mnohých prípadoch je celkom možné odstrániť informácie z internetu. Určite existuje záznam o webových stránkach, ktoré boli odstránené, ak hľadáte na webe Wayback Machine, správny? Áno, úplne. Na stroji Wayback sa nachádzajú záznamy o webových stránkach siahajúcich mnoho rokov - stránky, ktoré nenájdete pri vyhľadávaní Google, pretože webová stránka už neexistuje. Niekto to odstránil alebo došlo k odstaveniu webových stránok.
Takže sa to nedá obísť, však? Informácie budú navždy vyryté do kameňa internetu, aby ich mohli vidieť generácie? No, nie presne.
Pravda je, že hoci môže byť ťažké alebo nemožné vymazať hlavné spravodajské príbehy, ktoré sa šírili z jedného spravodajského webu alebo blogu na iný, napríklad vírus, v skutočnosti je celkom ľahké úplne odstrániť webovú stránku alebo niekoľko webových stránok zo všetkých záznamov o existencii - odstrániť túto stránku pre vyhľadávacie nástroje aj
Wayback Machine Nový stroj Wayback vám umožní vizuálne cestovať späť v internetovom časeZdá sa, že od uvedenia Wayback Machine v roku 2001 sa vlastníci stránok rozhodli vyhodiť back-end založený na Alexe a prepracovať ho pomocou vlastného otvoreného zdrojového kódu. Po vykonaní skúšok s ... Čítaj viac . Je tu samozrejme háčik, ale dostaneme sa k tomu.3 spôsoby, ako odstrániť blogové stránky zo siete
Prvá metóda je metóda, ktorú používa väčšina vlastníkov webových stránok, pretože nepozná nič lepšie - jednoducho odstráni webové stránky. Môže k tomu dôjsť, pretože ste si uvedomili, že na svojom webe máte duplicitný obsah, alebo preto, že máte stránku, ktorú nechcete zobrazovať vo výsledkoch vyhľadávania.
Stačí odstrániť stránku
Problém s úplným odstránením stránok z vášho webu je ten, že ste už stránku založili na webe sieť, pravdepodobne budú existovať odkazy z vašich vlastných stránok, ako aj externé odkazy z iných stránok na konkrétne stránky str. Keď ho odstránite, spoločnosť Google okamžite rozpozná vašu stránku ako chýbajúcu stránku.
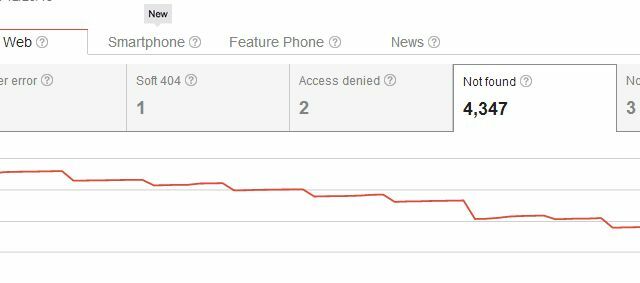
Odstránením stránky ste teda nevytvorili iba problém s chybami indexového prehľadávania „Nenájdené“, ale vytvorili ste problém aj pre kohokoľvek, kto na ňu niekedy odkazoval. Používateľom, ktorí sa na váš web dostanú z jedného z týchto externých odkazov, sa zvyčajne zobrazí vaša stránka 404, čo nie je závažný problém, ak používate napríklad vlastný kód 404 spoločnosti Google na poskytnutie užitočných návrhov alebo alternatívy. Mysleli by ste si však, že by mohli existovať elegantnejšie spôsoby odstránenia stránok z výsledkov vyhľadávania bez toho, aby sa všetkých tých 404 vykopali za existujúce prichádzajúce odkazy, však?
No, sú.
Odstránenie stránky z výsledkov vyhľadávania Google
Najprv by ste mali pochopiť, že ak webová stránka, ktorú chcete odstrániť z výsledkov vyhľadávania Google, nie je stránkou vášho vlastného webu, potom budete mať šťastie, pokiaľ neexistujú právne dôvody alebo ak web nezverejnil vaše osobné informácie online bez vášho povolenia. Ak je to tak, použite Google nástroj na riešenie problémov s odstránením odoslať žiadosť o odstránenie stránky z výsledkov vyhľadávania. Ak máte opodstatnený prípad, môže sa vám po odstránení stránky vyskytnúť určitý úspech - samozrejme, môžete mať ešte väčší úspech kontaktovanie vlastníka webových stránok Ako odstrániť falošné osobné údaje na interneteOchrana osobných údajov online už nie je zaručená. Naučte sa, ako nahlásiť webovú stránku a ako odstrániť osobné informácie z internetu. Čítaj viac ako som opísal, ako postupovať v roku 2009.
Ak je stránka, ktorú chcete odstrániť z výsledkov vyhľadávania, na vašom vlastnom webe, máte šťastie. Všetko, čo musíte urobiť, je vytvoriť robots.txt a uistite sa, že ste vo výsledkoch vyhľadávania zakázali konkrétnu stránku, ktorú nechcete, alebo celý adresár s obsahom, ktorý nechcete indexovať. Ako vyzerá blokovanie jednej stránky:
User-agent: * Disallow: /my-deleted-article-that-i-want-removed.html
Nasledujúcim spôsobom môžete zablokovať robotov v prehľadávaní celých adresárov svojich stránok.
User-agent: * Disallow: / content-about-personal-stuff /
Google je vynikajúci podporná stránka ktoré vám môžu pomôcť vytvoriť súbor robots.txt, ak ste ho ešte nikdy nevytvorili. Funguje to veľmi dobre, ako som nedávno vysvetlil v článku o štruktúrovanie syndikačných obchodov Ako vyjednávať ponuky syndikácie a chrániť svoje hodnotenie vo vyhľadávaníSyndikovanie je v dnešnej dobe zlosťou. Zrazu ste však zistili, že partner syndikácie je vo výsledkoch vyhľadávania uvedený vyššie ako vy pre príbeh, ktorý ste pôvodne napísali! Chráňte svoje hodnotenie. Čítaj viac aby vás neubližovali (požiadali partnerov syndikácie, aby zakázali indexovanie svojich stránok, na ktorých ste syndikovaní). Keď s tým súhlasil môj partner pre syndikáciu, stránky, ktoré boli duplikátom obsahu z môjho blogu, úplne zmizli zo zoznamov vyhľadávania.
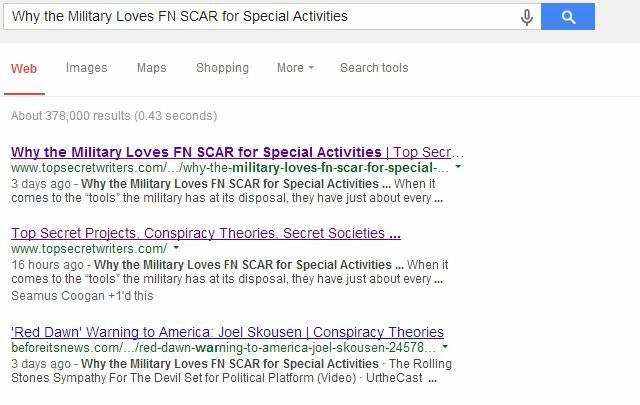
Na treťom mieste sa objaví iba hlavná webová stránka pre stránku, na ktorej je uvedený náš názov, ale môj blog je teraz uvedený na prvom aj druhom mieste; niečo, čo by bolo takmer nemožné, keby web s vyššou autoritou nechal duplikovanú stránku indexovanú.
Mnoho ľudí si neuvedomuje, že je to možné dosiahnuť aj pomocou internetového archívu (tzv. Wayback Machine). Tu sú riadky, ktoré musíte pridať do súboru robots.txt, aby sa tak stalo.
User-agent: ia_archiver. Disallow: / sample-category /
V tomto príklade poviem internetovému archívu, aby z Wayback Machine odstránil čokoľvek z podadresára vzorovej kategórie na mojej stránke. Internetový archív vysvetľuje, ako to urobiť na svojej stránke pomocníka Vylúčenie. Tu tiež vysvetľujú, že „Internetový archív nemá záujem ponúkať prístup k webovým stránkam alebo iným internetovým dokumentom, ktorých autori nechcú svoje materiály v zbierke.“
To letí na rozdiel od všeobecne uznávaného presvedčenia, že čokoľvek zverejnené na internete sa do večnosti zametá do archívu. Nie - webmasteri, ktorí vlastnia tento obsah, môžu obsah konkrétne odstrániť z archívu pomocou prístupu robots.txt.
Odstráňte jednotlivú stránku so značkami meta
Ak máte iba niekoľko samostatných stránok, ktoré chcete odstrániť z výsledkov vyhľadávania Google, v skutočnosti nemusíte používať prístup robots.txt. môžete na jednotlivé stránky jednoducho pridať správnu metaznačku „roboti“ a robotom povedať, aby neindexovali ani nesledovali odkazy na celom webe str.
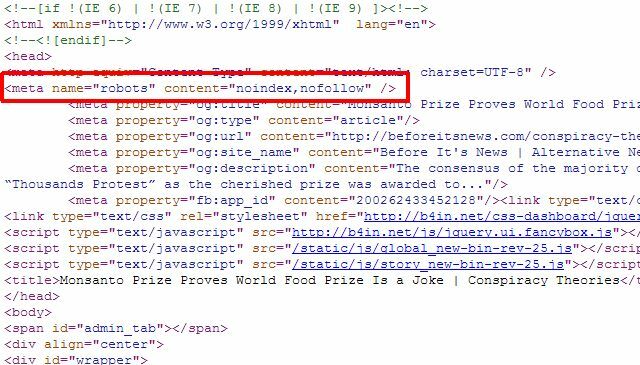
Môžete použiť metódu „roboti“ vyššie na zastavenie robotov v indexovaní stránky, alebo môžete konkrétne povedať robotovi Google neindexovať, takže stránka je odstránená iba z výsledkov vyhľadávania Google a k tejto stránke by mohli mať prístup aj ďalší vyhľadávací roboti Obsah.
Je úplne na vás, ako by ste chceli spravovať, čo roboty robia so stránkou a či je stránka uvedená alebo nie. To môže byť lepší prístup iba pre niekoľko samostatných stránok. Ak chcete odstrániť celý adresár obsahu, použite metódu robots.txt.
Myšlienka „odstránenia“ obsahu
Tento druh obracia na hlave celú myšlienku „odstraňovania obsahu z internetu“. Technicky, ak odstránite všetky svoje vlastné odkazy na stránku na svojom webe a odstránite ju z Vyhľadávania Google a internetu Internetový archív pomocou technológie robots.txt je stránka pre všetky zámery a účely „odstránená“ z internetu. Super je však to, že ak existujú odkazy na túto stránku, tieto odkazy budú stále fungovať a vy nespustíte 404 chýb pre týchto návštevníkov.
Ide o „šetrnejší“ prístup k odstráneniu obsahu z internetu bez toho, aby došlo k úplnému spochybneniu existencie odkazov na vašich stránkach na internete. Nakoniec, ako postupujete pri správe toho, aký obsah sa zhromažďuje vo vyhľadávacích nástrojoch a internetovom archíve, je len na vás, ale vždy nezabudnite, že napriek tomu, čo ľudia hovoria o životnosti vecí, ktoré sa zverejňujú online, je to naozaj v tvojom vnútri ovládanie.
Ryan má titul bakalára v odbore elektrotechnika. Pracoval 13 rokov v automatizačnom inžinierstve, 5 rokov v IT a teraz je aplikačným inžinierom. Bývalý šéfredaktor MakeUseOf, vystúpil na národných konferenciách o vizualizácii údajov a vystupoval v celoštátnej televízii a rozhlase.


